

To Teach a Machine
by Steven K. Roberts
Technology Review
January, 1982
My professional obsession in the early eighties was the intersection of the breathless microcomputer scene, cognitive science, the overhyped AI world, and publishing. I meandered through these communities as a geek dilettante, fueled by magazine assignments and my love of academic conferences… working on my textbook, sniffing after übergeekery, obsessing over new toys, and meeting authors who were at once intimidating and enthralling.
One inevitable discovery was that the most interesting things seem to happen at the boundaries between specialties, so those tended to be my shadowy haunts. Here’s one of my favorite tales from that epoch, written in September 1981 after a mind-bending 2-week jaunt to Stanford to hang out at Artificial Intelligence and LISP conferences, prowl the halls of Xerox PARC, and hobnob with people whose stoned idle musings spawned technological change. For a midwestern kid just getting started, this was seductive stuff.
This article written in the fall of 1981 is one of the results of that immersion, and it was a thrill to make it into the pages of Technology Review, the MIT publication that had long delighted me. Some of this is quaint now, and some yet idealistic… but I love that vertiginous feeling of approaching the cusp of something huge. (Had I known what I’d be carrying in my pocket 40 years later, not to mention casual chats with large language models, I would have cranked up my expectations another order of magnitude!)

Professor Henry Higgins wondered why a woman couldn’t be more like a man. Today’s concern is “why can’t a computer be more like a human?” But can computers ever “understand” human language and the complexities of human thought?
It has been less than a decade since microprocessors made their tentative debut amidst the entrepreneurial fervor of Silicon Valley, yet already the industry they spawned has made the long-predicted computer revolution a reality. The mystery that once shrouded “thinking machines” has been whisked away: even blenders and stereos now sport software-driven control systems.
But this technological dream is not untroubled. Though standard computer hardware is available for tasks that once required customized circuit design, somebody has to write the programs that make the hardware work. It is becoming ever more clear that programming—once considered the panacea for classical machine design headaches—has itself become a crisis of even greater magnitude.
The basic motivation behind the microprocessor industry was the desire for general-purpose hardware that would divert a large portion of the system design effort to manufacturers of integrated circuits. That is, the “chip vendors” would mass-produce logic components to perform data-manipulation functions. With standard circuitry applicable to a wide range of projects, designers could spend more time considering solutions to problems and less time doing battle with traditional aspects of hardware development.
That fantasy was quite reasonable when microprocessor applications were fairly simple, with programs ranging up to perhaps 20 pages of “code” (the instructions that direct the machine’s activities). But memory became cheaper and cheaper, and soon substantially more complex microprocessor applications became feasible. Programs consisting of several hundred pages of code appeared, and the sophistication of software development tools grew erratically to accommodate the ever-increasing flexibility of the hardware. But the burden remained on the programmer, for the tools couldn’t keep up. What was needed was another evolutionary development—like the microprocessor—that would allow engineering efforts to be shared with vendors via standardized programs for common problems.
But what actually appeared was a confused jumble of non-standardized high-level computer languages. Communication between programmers and management, programmers and customers, and even programmers and programmers became more and more erratic as the hope that any program could be used on any computer was shattered on the rocky shores of conflicting philosophies. Documentation—the written explanation of a program—ranged from inconsistent to nonexistent. And the general efficiency of software development declined as project complexity increased, for programming was still a human task and could not take advantage of the production techniques that made the hardware revolution possible.

There were no established testing techniques, nobody was really sure how software should be specified, and to top it off, there was an ominous shortage of programmers. The lack of good management techniques for software design ensured the proliferation of “hotshots” who insisted on doing things their own way, keeping the field unmanageable and attracting more of the same. The software design business became exclusive, frightening newcomers with its profusion of obscure concepts and arcane notational schemes.
Nobody came out ahead during these turbulent years (with the possible exception of chip vendors, who strode profitably through various recessions with nary a glitch in their exponential growth curves). Programmers became disenchanted, managers found themselves helplessly watching production schedules go awry, and customers—those trusting souls whose money kept the whole industry alive—found themselves with giant aggregates of undocumented code incomprehensible even to the original programmer.
Communicating the Unspeakable
What is this thing called software that is causing so much trouble? What, indeed, can be done?
Perhaps the best way to approach such questions is to begin at the top—with the human thought processes that, after suitable distillation, become programs. One of the hallmarks of intelligence, at least as humans see it, is the ability to manipulate symbols—to represent the universe internally in symbolic form and communicate with one another through linguistic representations of these internal models.
These symbolic processes that depend upon association are the fundamental operating characteristic of the brain. Unlike computers, which represent data via explicit references located at precise “addresses,” brains represent information associatively (note the use of the words “data” and “information”). A new item—be it sensory input, abstract insight, or acquired fact—is integrated with related information in an exquisite web that allows us later access via a number of pathways.
The mechanism by which all this occurs has been widely speculated upon, but there seems to be a gap between investigations of neuron and synapse behavior in the brain (the “device” level) and cognitive modeling (the “system” level). One of the more interesting theories is that information is distributed across a structure, as in a hologram, rather than existing in isolated cells (as in a typical computer system). This theory is supported by observations concerning our levels of perception: we remember a scene not as an array of dots but as a fully-dimensional echo of the original perception, the detail of which depends on its association with other memories. For example, if you walk into a room, you remember not a precise image of the room in balanced detail but a general gestalt, highlighted by more complex memories of items that particularly spark your interest.
It has even been observed that widely variant memories are stored in the same areas of the brain. In fact, portions of those areas can be surgically excised without grossly affecting the memories (just their texture or resolution), but even with infinite medical finesse you could not remove an isolated bad memory.
Tough Talking with Computers
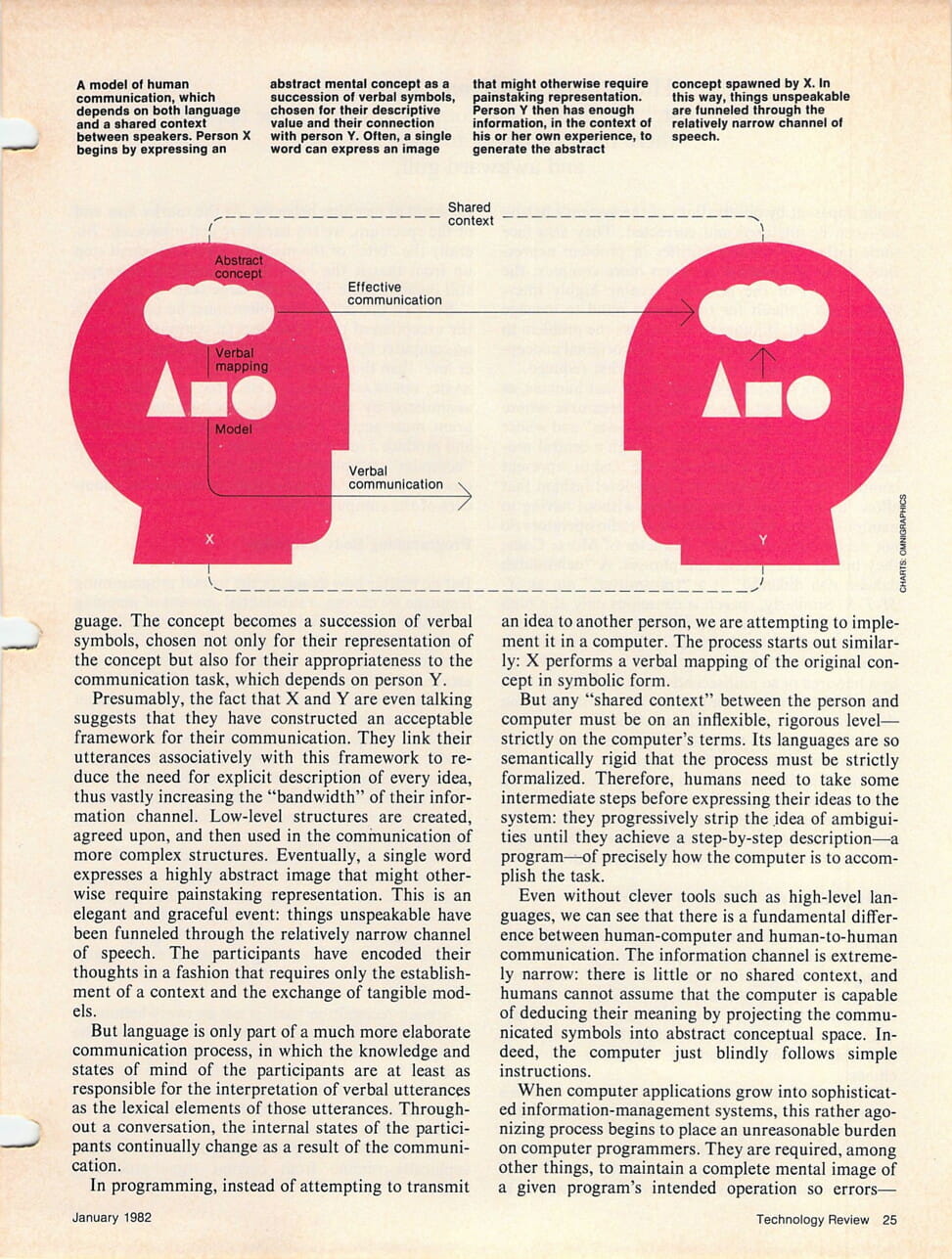
In communication between people, person X begins by projecting a deeply associative abstract concept onto the somewhat more tangible fabric of language. The concept becomes a succession of verbal symbols, chosen not only for their representation of the concept but also for their appropriateness to the communication task, which depends on person Y.
Presumably, the fact that X and Y are even talking suggests that they have constructed an acceptable framework for their communication. They link their utterances associatively with this framework to reduce the need for explicit description of every idea, thus vastly increasing the “bandwidth” of their information channel. Low-level structures are created, agreed upon, and then used in the communication of more complex structures. Eventually, a single word expresses a highly abstract image that might otherwise require painstaking representation. This is an elegant and graceful event: things unspeakable have been funneled through the relatively narrow channel of speech. The participants have encoded their thoughts in a fashion that requires only the establishment of a context and the exchange of tangible models.
But language is only part of a much more elaborate communication process, in which the knowledge and states of mind of the participants are at least as responsible for the interpretation of verbal utterances as the lexical elements of those utterances. Throughout a conversation, the internal states of the participants continually change as a result of the communication.
In programming, instead of attempting to transmit an idea to another person, we are attempting to implement it in a computer. The process starts out similarly: X performs a verbal mapping of the original concept in symbolic form.
But any “shared context” between the person and computer must be on an inflexible, rigorous level— strictly on the computer’s terms. Its languages are so semantically rigid that the process must be formalized. Therefore, humans need to take some intermediate steps before expressing their ideas to the system: they progressively strip the idea of ambiguities until they achieve a step-by-step description—a program—of precisely how the computer is to accomplish the task.
Even without clever tools such as high-level languages, we can see that there is a fundamental difference between human-computer and human-to-human communication. The information channel is extremely narrow: there is little or no shared context, and humans cannot assume that the computer is capable of deducing their meaning by projecting the communicated symbols into abstract conceptual space. Indeed, the computer just blindly follows simple instructions.
When computer applications grow into sophisticated information-management systems, this rather agonizing process begins to place an unreasonable burden on computer programmers. They are required, among other things, to maintain a complete mental image of a given program’s intended operation so errors— made apparent by observations of the system’s behavior—can be analyzed and corrected. They also face some rather formidable hurdles in problem expression, for as the concept becomes more complex, the various parts of the program became highly intertwined and difficult for the human mind to manage all at once. But, if humans can express the problem to the machine at a level closer to their original conception, then chances of error are somewhat reduced.

Part of the reasoning behind this is that humans, as we have suggested, are associative creatures whose memories do not have specific “addresses” and whose operations are not compressed through a central processing site, as with a computer. We tend to represent complex arrays internally in a high-level fashion that allows us to extract their meaning without having to manipulate bits. Ham radio operators do not decode each individual character of Morse Code; they inhale entire words and phrases. A “dahdididah dahdah dah didahdit” is a transmitter, not an X-M-T-R. Similarly, speech is conscious only at a high level: saying the word “speech,” for example, is hardly accomplished by deliberately letting fly with an unvoiced sibilant, then doing a labial plosive followed by a hundred or so milliseconds’ worth of voicing with a constricted forward tongue hump, at last wrapping the whole thing up with a carefully contrived unvoiced tongue-to-gum-ridge stop that immediately turns into a fricative on the hard palate.
What this all boils down to is that people are much more comfortable thinking what, not how. But computers are just the opposite—they have no idea what, they just accept the how and go to work. There must be a way to span this vast and awkward gulf.
Moving Along the What-How Spectrum
People were content in the “old days” to talk to computers on the machine’s level—perhaps they were enough of a novelty back then that nobody was terribly upset about the philosophical implications. Even if they were, it wouldn’t have done any good anyway. There were no assemblers, interpreters, compilers, operating systems, editors, or simulators—just machines.
There are various degrees of synchrony between computers and humans, shown more or less arbitrarily in the figure on page 28. This model is often used in the artificial intelligence field to express the relative sophistication of a system, specifically the level of expression necessary to implement human wishes in the form of machine behavior. At the murky how end of the spectrum, we see hardware and microcode, literally the “bits” of the machine. One very small step up from that is the basic binary machine language, still incomprehensible on any large scale to humans.
But past this point, a problem must be faced. With the exception of new experimental computer designs, no computer system can deal with anything on a higher level than this rather gritty code. For a program in BASIC, FORTRAN, PASCAL, LISP, ADA, or COBOL to be assimilated by the computer, an intermediary program must accept a high-level problem description and produce a lower one. In other words, we can use a “compiler” or “interpreter” to shift some of the onerous burden of what-to-how conversion onto the shoulders of the computer itself.
Programming Body Language
But no matter how exquisite the formal programming language we choose, a substantial amount of mapping must still be done. We may not have to describe the method of performing a square root, but we still have to determine when a square root is appropriate and ascertain that the proper data are used. Wouldn’t it be nice if we could just state the problem verbally and let the machine deal with the details of solving it? This image of computer use has been popular with the media since the time of Charles Babbage, the English mathematician who pioneered primitive “computers” in the mid-nineteenth century, but only recently has it seemed even remotely possible that such a luxury may indeed be in the offing.
The field of artificial intelligence, concerned with the implementation of symbolic thought in computer systems, is already leaning heavily in that direction. There is an active subspecialty called “automatic programming,” and the study of natural language comprehension—that is, teaching computers to recognize human speech—occupies a large number of researchers full-time.
Speech recognition itself is not an overwhelmingly difficult task, so long as we are basically asking the computer to match an utterance to an array of words already in the system’s vocabulary. The problem begins to appear formidable when the size of the necessary vocabulary grows, and the performance goes all to pieces when it is asked to deal with more than one human speaker. Still, speech recognition is not philosophically remote from current signal-processing tools.

But that’s not the issue, however. Once a sentence has been assimilated (or simply typed in—let’s start small), a vastly different problem confronts the computer. A programmer might say, “Ah, let’s see, put the other cover plate on top of it, line it up with the holes, and screw on the cover.”
What is “ah”? There are three cover plates—which “other” one? Line what up? Which holes?
The intent of that verbal instruction is substantially greater than suggested by its explicit linguistic content. As noted, a context is inextricably linked with the spoken words, giving depth to the symbols and antecedents to the pronouns. Somehow, the computer must incorporate this contextual information into the process of decoding the natural language. This is a rather awesome problem, for if it is truly to “understand,” it must possess a large body of common sense.
If the human says, “Ah, let’s see….” the computer is probably not being directed to fire up its vision system and begin frantically performing sophisticated mathematical operations—it must recognize the expression as an essentially nonfunctional placeholder. When the human says “screw on the cover,” the machine must know what screws are, how to make them turn, which way to turn them, how much torque should be applied, and when to quit.
Nor is this required body of common knowledge a static accumulation of data. In human conversation, the shared context is as fluid and vital as the sounds that fill the air; more so, in fact, since the true communication is an amalgam of expectations, intuitions, visual cues, vocal tonalities, evoked memories, touches, rational deductions, and, oh yes—words. Clearly, the information bandwidth of the human-machine link is intrinsically limited, no matter how cleverly we can contrive it. It is going to take a mighty sophisticated processor to note the “body language” of the human converser and subtly modify the derived meaning accordingly.
The point is that it becomes exceedingly difficult to view natural language as distinct from intelligence. For the idea of “teaching a machine” to have any validity, we must develop systems that can address applications not already encoded in their very fabric. We must develop systems with a common-sense understanding of physics, a knowledge of human psychology, and a readily accessible “meta-knowledge” that enables them to know whether they know something without having to exhaustively search a database. Further, we must develop systems capable of using sophisticated communication skills to compensate for a lack of knowledge or capability—by making appropriate queries and investigations.
Somewhere during this evolutionary period, there will be a subtle shift from programming to teaching to interactive dialogue. The meanings of words at first will be inseparable from functions, but as a system’s intelligence reaches the threshold beyond which learning can take place, words become more symbolic and less action-oriented—the machine’s capabilities become more abstract. It begins to “think” symbolically, metaphorically, perhaps even appreciating the context switches that underlie humor, the mingling of levels that gives meaning to art, and the recursive introspection that eventually must be acknowledged as consciousness.
Language is the key to all of this. Only with the increased coding depth of symbolic communication can we seriously consider turning over some of the what-to-how conversion to machines.

Programming Today and Tomorrow
Consider a typical industrial control system. The programmer chews on an idea for a while, then writes code that supposedly tells a microprocessor how to interact with the manufacturing equipment to save the company money on material and tooling costs. The computer, of course, has no idea what it’s doing—it has no conception of its task. It does have an internal model of the world, but it is so primitive compared to the programmer’s that it could be unplugged, carried to a remote (but electrified) mountain peak, plugged in again, and resume execution of the control loop with quiet assurance that everything was normal.
The real problem is the spanning of the vast conceptual gulf between people and machine. And although the technology now includes a variety of software tools and other techniques to ameliorate the onerous burden of mapping an abstract concept onto a precise sequential pattern of machine-level instructions, success has been limited. In addition, the computer population is increasing faster than the human one, and programmer efficiency must be increased accordingly.
Another (r)evolutionary development comparable to the microprocessor hasn’t yet materialized: programming can barely keep pace with hardware development. Difficulties exist at almost every level in the conversion of a task from what to how. Formal expression of software problems is difficult: management commonly leaves such things to the programming group, preferring to criticize the result rather than create unambiguous task definitions in the first place.
It is uncertain whether software design is an art or a discipline. Programs are rarely documented well enough to make them useful to someone else. Languages don’t quite fit other machines. Testing a finished piece of code is a chancy business, with exhaustive analysis of all possible states nearly impossible. On-site software modification costs a fortune.
And few people even have a clear idea of what constitutes good software. The standard definition is simply “a program that works.” But even a badly designed programming potpourri—finally beaten into hesitant operation after months of cursing and debugging—can be said to “work.”
Of course, human programmers must don a formal intellectual straitjacket when attempting to convert a conceptualization into its coded form. The generally accepted complexity of this task has spawned a number of elaborate disciplines, among them the body of precepts known as “structured design.” The intent here is a universal methodology that simplifies the programming task by modularizing it—establishing a hierarchy of clearly defined, independent functions. Programmers can handle these relatively isolated units more readily than the amorphous aggregates of code that would result from a more arbitrary approach.

Interestingly, the general objective of this structured-design philosophy is the creation of a “top- down” system loosely comparable with the organization of a well-run bureaucracy. This approach readily allows for formal documentation, exchange of modules among programmers, and perhaps most important, effective management.
However, structured-design techniques, like the programming languages themselves, are simply tools. Like the tools of the manual trades, they do not guarantee brilliance or even high-quality results—they can be wielded by laborer and artist alike. They can enable users to wreak havoc or to create a sublime masterpiece. There has been an unfortunate temptation in the industry to let sophisticated tools define the shape of the work to which they are applied.
At its heart, the teaching of machines is a creative endeavor. Software design is an art solidly supported by sophisticated engineering disciplines—but art without engineering is dreaming, and engineering without art is calculating.
New high-level structured languages (such as ada), innovative “object-oriented” languages (such as Smalltalk), and ongoing developments in automatic programming and natural-language processing promise considerable change in the years ahead. The days of detailed, low-level coding are numbered except in situations where machine process timing is critical, and the “high-level” languages of today will give way to the even higher-level ones of tomorrow. We are indeed moving toward a time when problems can be expressed to computers in symbols much more congruent with human thought than the step-by-step descriptions of today’s programs. But until then, we can expect the software business to be ever more frantic, drawing heavily but self-consciously upon the wizardry of individual programmers to make the necessary leap between what and how.
Steven K. Roberts, a consulting engineer in small computer systems, alternates between writing and software design. This article is adapted from his forthcoming book, Industrial Design with Microcomputers (Prentice- Hall).

Reprint in Management Digest
May, 1982
The American Management Association picked this up shortly after its appearance in Technology Review, and the text is essentially identical (although tightened slightly for the business audience). Rather than redundant OCR, I’ll just show the page images below:




You must be logged in to post a comment.